I still think about one migration project where everything was green until the final month. We did not have the luxury of extending the deadline. This was tied to external regulation and compliance, so missing the date was not really an option. We had to make it. Up until that point, the project had been reported as green. Then, almost all at once, reality caught up with the reporting. Two teams were struggling to deliver the final task, and what had looked manageable from a distance suddenly became very red at the last mile.
What happened next was, in one sense, good engineering. We stopped debating and attacked the problem. We pulled in people fast. We went to data. We looked at concrete signals instead of general confidence. Error X was at 0.2%. Error Y was at 0.3%. We assigned engineers directly against the failure modes we could see, while continuing the rollout carefully enough to surface whether more problems were waiting behind the first wave. In the end, we made it.
But I would not call that a healthy success.
For almost a month, we had to stop the world and turn the organization into a bug hunt. We poured in every resource we could get. Engineers were tired. Leadership got a very different signal from the one they had been receiving for months. And the part that stayed with me was not only the stress of that final stretch. It was the uncomfortable question underneath it: how did something remain green for so long if the last mile required this level of emergency concentration?
That experience stuck with me because it exposed a pattern I have seen more than once. Status does not usually become dishonest in one dramatic moment. It gradually slides. A project is green because nobody wants to create noise too early. Then it stays green because people hope they can recover quietly. Then the remaining uncertainty gets compressed into the final stretch, where the only available move is brute force. By the time the status finally turns red, the organization has already lost the chance to maneuver.
That is why I do not think honest status reporting is mainly a communication skill. I think it is a system problem. If truth depends on somebody being unusually brave at exactly the right time, the system is badly designed. And if green can survive all the way until the last mile, what failed is not just reporting. What failed is the structure around it.
That is the part I want to focus on in this post. Not how to sound more transparent, but how to build a system where transparency has a chance. I want to look at the rules, artifacts, and escalation mechanics that make it harder for teams to drift into polite fiction, and easier to surface reality while there is still time to do something useful about it.
 How Green Slowly Turns into Chaos
How Green Slowly Turns into Chaos
Rules Before Templates
Before you talk about status formats, dashboards, weekly updates, or project review rituals, you need rules. Otherwise people will take a weak system and simply pour it into a nicer template. Reporting polish doesn’t help with underlying behavior.
That is why I think of this as an honest contract. It's not a document, necessarily. It's more like a set of operating rules that define what honest status is allowed to look like. If those rules are missing, you might find yourself drifting into politeness, vagueness, and proof-of-effort reporting. If the rules are clear, reality has somewhere to stand.
No Risk Without a Next Move
One of the easiest ways to make a status update sound responsible without actually making it useful is to mention a risk in a vague, emotional way. “There is some concern around performance.” “We are keeping an eye on the dependency.” “Testing is a little tight.” This creates the feeling of transparency, but not the operational benefit of transparency.
A risk is not a mood. We, in software development, mostly take it as a gut feeling. It hast to be an evaluation of a situation with consequences. And it has to come with a next move. It can be mitigation, containment, or a decision request. But there has to be a bridge between naming the problem and changing the outcome. Otherwise the update brings anxiety to everyone. At each risk junction, you want clarity, actionability, and accountability.
No Escalation Without Options
Bad news lands differently when it arrives with structure. “We are behind” is not enough. Behind in what way? What can still move? What is fixed? What are the available trade-offs?
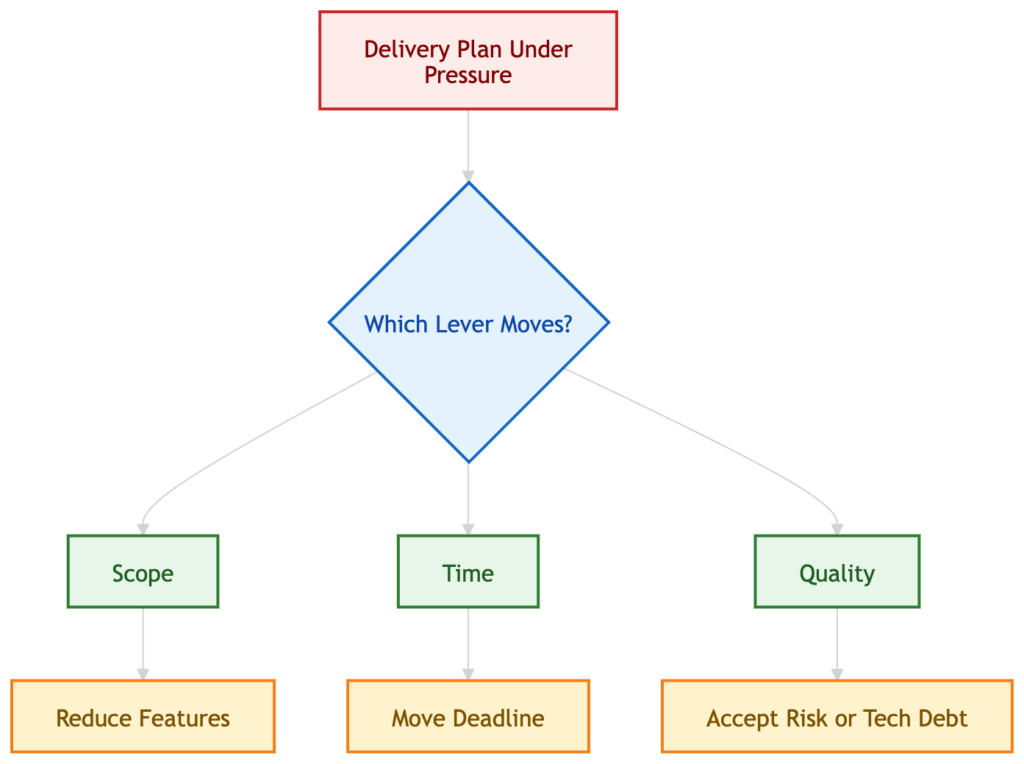
When you escalate, you should usually bring options. In delivery work, these options tend to collapse into the same three levers again and again. Cut scope, move the date, or accept some quality cost. The exact wording may change, but the underlying economics do not. Someone has to pay. Honest status means making that payment visible.
Unfortunately, ambiguity protects everyone in the short term. If you simply say the project is at risk, people can keep pretending there is a fourth option hiding somewhere. Usually there is not. Escalation gets useful only when it forces an actual choice.
No Dependency Without a Handshake
I have seen “waiting on Team X” appear in enough status reports to know that it often means almost nothing. Was there a clear ask? Was the format defined? Was there an owner on both sides? Was there a date? Was the consequence of delay explicit? Or did everyone nod in a meeting and walk away with slightly different interpretations?
This is why I like the idea of a dependency handshake. If one team depends on another, the dependency should be concrete enough to behave like a small contract. What is needed. In what format. By when. From whom. And what happens if it slips.
Without that handshake, what looks like a dependency is often just wishful thinking with messages around it. Then the status report says “blocked on Team X,” as if that is a natural weather condition. It is not. It is usually an undocumented contract failure.
No Recurring Meeting Without an Output
A lot of status dysfunction survives because meetings give it shelter. People gather, narrate motion, ask a few polite questions, and leave with the same ambiguity they brought in. The ritual creates a feeling of control, but the work itself has not moved.
I think a recurring meeting should justify itself very simply. It should produce one of three things: a decision, a plan, or alignment on a blocker. If it does not do one of those, it is probably a status theater. Those are expensive.
Ban Proof-of-Labor Reporting
One of the most common anti-patterns in engineering communication is to confuse activity with progress. Long lists of what people worked on. Story points. Hours spent. Meetings attended. Threads answered. None of these are meaningless, but none of them automatically tell you whether the work is moving toward a viable outcome.
The purpose of status is not to prove that engineers are busy. It is to clarify movement, risk, and pending decisions. Once a team starts reporting effort performance instead of trajectory, visibility weakens. People begin optimizing for visible busyness rather than decision-quality and delivery truth. This is exactly the kind of proxy drift that shows up elsewhere too: once evaluation pressure gets attached to the wrong signal, behavior bends around the signal.
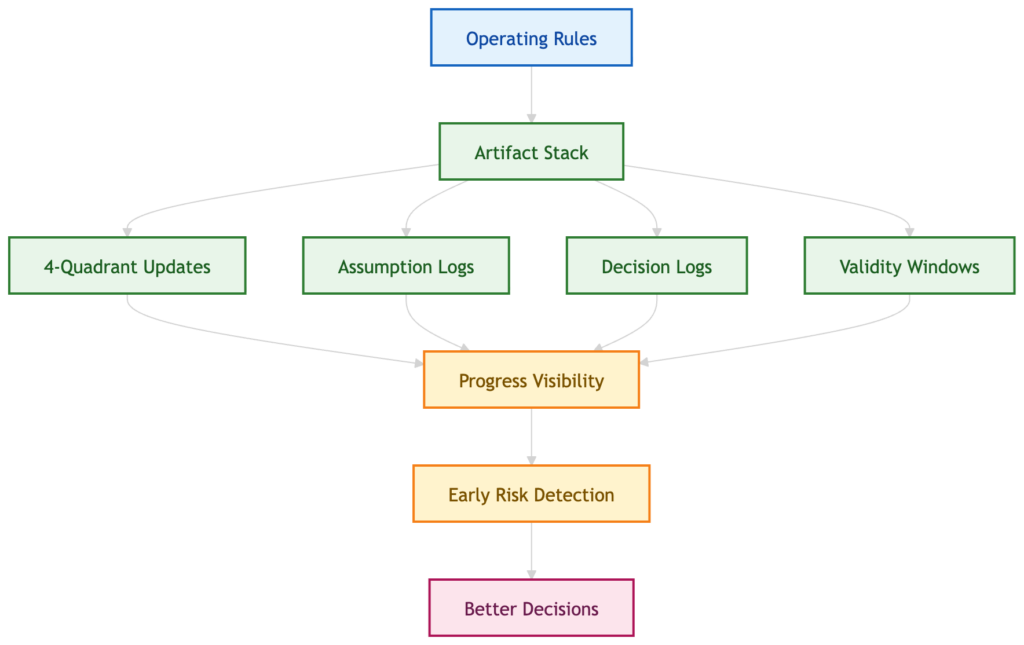
The Artifact Stack
Once the operating rules are clear, the next question is simple: what are the smallest written artifacts that make those rules real? A good artifact stack should make progress visible, risk harder to hide, and decisions easier to force. The goal is not to produce more reporting. The goal is to make status more defensible. That’s how you make good execution without performatory reporting.
 honest status system
honest status system
The 4-quadrant Async Update
If I had to keep only one status artifact for normal delivery work, it would probably be this one. Not because it is elegant, but because it forces the right compression. A good async update should answer four things:
- what moved in the last period
- what is expected to move next
- what currently threatens that movement
- and what decision is now required from someone else.
That structure matters because it pulls the update out of narration and into coordination. With this structure, you reduce cognitive load while making movement, risk, and choice sit in the same place. More importantly, it creates a better question. Not “did the team work hard?” but “is the work still on a credible path?”
Validity Windows for Green
One of the biggest flaws in normal status reporting is that green often behaves like a feeling. It appears, then remains in place until reality becomes too obvious to ignore. That is how a project can stay green for months and then suddenly become red in a way that is technically surprising but operationally obvious.
I think green status should have conditions attached to it. It doesn't have to be complicated ones, just explicit ones. Green until you rolled it out to three prod environments by week X. Green unless scope changes again. Green until your dependency isn't postponed. The point is to stop green from becoming permanent optimism. Once a status has a validity window, it behaves more like an engineering claim.
Green simply cannot be a mood or gut feeling. It should be a claim with an expiry condition.
Assumption Logs
If validity windows tell you when a status expires, assumption logs tell you what that status depends on in the first place. A lot of delivery reporting is weak not because the writer is hiding something, but because the update depends on top of a few unstated assumptions. Your redis cluster support arrives in a month. No new architecture push back for the new component. No new security requirements appear before cutover. None of these are inherently unreasonable. The problem is when they remain invisible.
An assumption log is useful because it drags conditional reality into the open. It tells everyone that the current confidence level is not free-floating. It is attached to a set of things that may or may not happen. That shifts the conversation from “why did the project suddenly turn amber?” to “which assumption broke, and what should that do to the plan?” It is a much healthier question.
This is also one of the simplest ways to reduce false surprise. Many projects do not drag because nobody saw the risk. They fail because the risk stayed implicit long enough to feel like bad luck when it materialized. These assumptions also help whether you want to pull the plug from the project or not.
Decision Logs
I think of decision logs in the practical memory sense. Teams make trade-offs under uncertainty. They choose one migration path over another. They defer a cleanup. They accept a temporary workaround. They decide not to build the more robust thing because the date, cost, or compliance pressure says otherwise. A few weeks later, someone re-enters the discussion with new information and asks why the “obvious” decision was not made earlier. That is a predictable so it should be covered by decision logs.
Embedding decision logs to your culture help because they preserve context, not just conclusions. What did we know at the time? What options did we reject? What consequence did we knowingly accept? Without it, organizations relitigate history using information they did not have at the moment of choice. Then blame might get rewritten after the fact.
Deterministic Signals Where Useful
Used well, deterministic signals can reduce the courage tax of speaking up. If cycle time blows out, if error rate crosses a threshold, if the test pass rate drops, if the critical path issue count grows beyond an agreed level, then the system itself starts surfacing the problem. That helps because it removes some of the political load from individuals. The engineer no longer has to be the sole bearer of unwelcome news. The signal helps carry it.
Bad News Mechanics
Most teams fill their narrative with hope, delay, soft language, and one more attempt to recover quietly. By the time the issue is finally escalated, the cost is higher, the options are worse, and the emotional charge is stronger than it needed to be.
That is why bad-news mechanics matter. If the organization wants honesty, it cannot rely on personal bravery alone. It has to make bad news easier to deliver, earlier to surface, and more structured once it arrives. Otherwise “be transparent” becomes one of those management values that sounds noble but collapses on contact with real deadlines.
Quantitative Escalation Thresholds
One of the cleanest ways to reduce hesitation is to decide in advance what automatically triggers escalation. A lot of teams technically have permission to raise concerns, but in practice they are still asking individuals to make a social judgment call. Is this bad enough yet? Is it too early? Am I overreacting? Will this create noise? Should I wait one more day and see if we recover? That internal debate is where truth often gets delayed.
Hard thresholds help because they remove some of that ambiguity. If a dependency slips by more than a week, escalate. If critical-path scope grows beyond an agreed amount, escalate. If the regression suite is still incomplete two days before cutover, escalate. If a blocker remains unresolved for more than one business day, escalate. The exact numbers matter less than the principle. The point is to move escalation out of the emotional domain and into the operating model.
Iron Triangle Conversations
A surprising amount of status dishonesty exists because people want to postpone a trade-off they already know is coming. The work expands, or a dependency slips, or the solution proves more fragile than expected, but the conversation still behaves as if scope, time, and quality can all remain fixed. That is where vague status language becomes useful. It buys time against the moment when someone has to say the obvious thing: something has to move.
 Iron triangle conversation
Iron triangle conversation
That is why I think bad news should often be framed through the iron triangle. If the plan is under pressure, which lever are we moving? Scope, time, or quality? You can phrase it more elegantly if you want, but at some point the underlying economics should become visible.
Disagree and Commit
Not every bad decision can be prevented. Sometimes engineering gives its assessment, the business chooses a riskier path, and the team still has to execute. That is exactly where memory becomes political.
If that moment stays verbal, it tends to get rewritten later. People remember optimism and forget the caveat. They remember alignment and forget the disagreement. They remember that “everyone agreed” even when the engineering assessment was materially different. Then when the cost arrives, blame spreads in a foggy, convenient way.
A simple written receipt helps. Not dramatic. Not defensive. Just clear. Engineering assesses that Option B introduces X risk and Y likely consequence. Given the stated priority, we will proceed accordingly.
The Dead Rat One-Pager
Most struggling projects have many problems. Some have one problem that is doing most of the damage. A key dependency that is not arriving. A migration path that does not hold under real traffic. A design assumption that turned out to be false. A missing capability that was treated like a detail and is now load-bearing. In those moments, normal status language becomes dangerous because it spreads attention too evenly. Everything sounds mildly concerning, which hides the fact that one issue has already broken the credibility of the plan.
That is when you need the dead-rat one-pager.
The point is simple. Stop narrating around the problem. Name the single bottleneck that makes the current plan untrue. Explain what it blocks, what assumptions it invalidates, and what choices now exist. The purpose is not to dramatize. It is to force concentration. A project cannot recover if the organization keeps pretending the main issue is just one bullet among many. Sometimes honesty requires compression. One page. One dead rat. One reason the plan is no longer real.
In Conclusion
Honest status reporting is not about better wording. It is about whether truth can surface early enough for the organization to still have options.
If risk can be mentioned without a next move, if dependencies can drift without a clear handshake, if green can survive without conditions, and if escalation depends on personal courage rather than pre-agreed triggers, then status will slowly detach from reality. At that point, the report stops being a reflection of the work and becomes a buffer between the work and the people who need to respond to it.
The cost is not just confusion. It is late trade-offs, tired engineers, and brute-force recovery at the point where precision would have been far cheaper. A good status system does not remove bad news. It lowers the cost of telling the truth. That is what transparency should mean in engineering: not bluntness, not alarmism, just a system where reality reaches the surface while there is still time to do something intelligent about it.