I’ve been asked once to design a key value store in an interview. It looks easy at first. Then it gets hard, fast. What makes it interesting is how ambiguous it is. I started using it for interviewing staff+ level myself as well, because the ambiguity is really hard to get right.
I like this question because you can approach it from a dozen angles. Another reason is people will solve it differently. Not everyone specializes the same way, so people care about different aspects. That difference in perspective also makes it more fun, to be honest.
However, I think many people get the basics wrong. Once that happens, it becomes harder to iterate. The one thing you want to get right from the get-go is really understanding the requirements for any system. I teach this in university as well. The better you capture requirements, the easier it becomes to design it. In practice, if you understand your customer, it’s easier to build solutions for them.
The same principle applies to system design. If you understand the problem space, the likelihood of solving it becomes a much bigger thing. Because of that, whatever you do, start asking questions that drive requirements. Don’t worry about getting everything right. Instead, think of it like binary search. You want to ask a few questions to get closer to the value you are searching for. Importantly, they should be logically related. This matters because it also shows the interviewer that you’re able to analytically reason about a question.
With that framing in mind, let’s try to answer this question. Keep in mind that each version of this problem can go anywhere.
Start With the Story
Before requirements, I want a one-breath story, who uses this store, and what pain we are actually solving. I like candidates who ask about it. It tells me they care about business outcomes. Like why would you build such a thing in the first place. Here’s a story for it.
Let’s think of a realistic use case here. We might be a platform team running an online entity store for real-time production decisions. Services call it on the hot path to fetch small per-entity blobs keyed by something like user_id, device_id, or item_id, for example feature vectors for ranking, user state for personalization, fraud signals, entitlement state, or request metadata needed to make a decision in a single network round trip. Some real deployments also need TTL, but for this exercise we keep the contract to just Get and Put and treat expiration as out of scope.
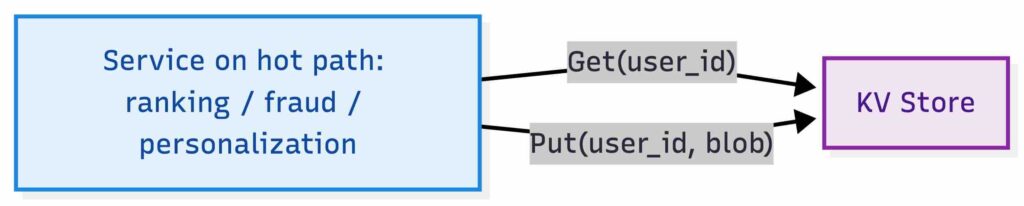 Key Value Store Usage
Key Value Store Usage
The key requirement is callers do not want to think about shards, nodes, or topology. They just want it to work. They want a simple contract: Get and Put, low tail latency under load, and predictable behavior in the event of failures. Otherwise we might drift into database fantasies.
Getting the Requirements
Before drawing boxes or talking about replication, this is where the conversation must start. A key/value store is deceptively simple, and if we skip requirements, we almost guarantee a wrong design.
I usually split this into functional and non-functional requirements first. Nothing fancy. Just enough to anchor the rest of the discussion. This should apply to almost all system design interviews.
Functional Requirements
At its core, the system supports two operations:
- Get(key: string) → value: string
- Put(key: string, value: string)
That’s it. No scans. No transactions. No secondary indexes. No deletes. If you start adding random features here, you are solving a different problem. This simplicity is intentional. If someone starts adding features here without being asked, it’s usually a red flag that they’re solving an imagined problem instead of the actual one. This is literally YAGNI. Do not build extra stuff because it sounds impressive. We are already trying to impress in an interview!!
Why no deletes? Deletes in distributed systems introduce tombstones, which must propagate to all replicas and eventually be garbage collected. This adds compaction complexity and can cause "resurrection" bugs if not handled carefully. For this exercise, we treat it as out of scope, but a real system would need to address it.
Why no TTL? A cache like system often needs it, but TTL is effectively time based delete. Therefore, same problems to deal with. To keep the core design focused, we treat TTL as out of scope. In a production system, you would add a Put(key, value, ttl) variant, implement lazy expiry on reads, and run background cleanup.
For this exercise, we'll skip TTL to keep the core design focused. Yet, if someone asks about deletes or TTL is again a good sign. They know and have been using similar systems.
Non-Functional Requirements
If someone got the functional requirements right, the next step is non-functional requirements. I know this sounds easy but it’s not. People really don’t ask questions and clarify what they are supposed to design. Anyway, non-functional requirements are where the real constraints show up. I would expect a few questions to clarify the following constraints.
- 4 TB of total data
- Latency target: 20 ms
- Throughput: 100000 requests per second
Before doing any math, we need to assume key and value sizes:
- Average key size: 64 bytes
- Average value size: 1 KB
- Max value size: 64 KB (reject larger)
This gives us roughly 4 billion keys to store (4 TB / 1 KB). If values were 1 MB instead, we’d only have 4 million keys. Slightly different problem. Note that 4 TB in RAM is not the same as 4 TB of raw value bytes. At this scale, per-entry overhead such as hash tables, pointers, allocators, version metadata, fragmentation can increase memory cost significantly.
We should also clarify the read/write ratio. Assume:
- 90% reads, 10% writes
This is typical for cache-like workloads. A write-heavy workload (50/50 or worse) would push us toward different optimizations: batching writes, async replication, and careful WAL throughput planning.
With these constraints at hand, we already got enough hints to see where this might go. They force questions like:
- Can this fit on a single machine?
- Is disk access acceptable, or do we need memory?
- Are we optimizing for tail latency or average latency?
- Do we need strong consistency?
 Key-value store requirements tree
Key-value store requirements tree
What Good Looks Like
Before we go deeper, I like to define success in plain language. Otherwise we end up debating what good looks like later on. For this exercise, success usually looks like:
- P99 latency stays under 20 ms at steady state.
- Availability target is explicit, for example 99.9%, because that drives replication and operational posture. Every 9 we add here, it’ll get increasingly harder, and can become a different problem. Let’s be conservative.
- Our durability requirements are also a bit relaxed, losing the last 10 seconds of data is fine. This isn’t a database.
This is the business acumen part of system design. Every box we add costs money and complexity, so I want every major decision to map back to one of these goals. At this stage, I don’t want answers yet. I want candidates to pause, sanity-check these numbers, and ask clarifying questions. This is the moment where good system designers slow down instead of rushing forward. From here, everything else, storage choice, partitioning, replication, follows naturally if these requirements are truly understood.
Diving Deeper
With the basics right, now we can move into more involved pieces. Disk space keeps getting cheaper and disks keep getting faster, so a disk from ten years ago versus today is a very different thing. Still, having a ballpark understanding matters, because it is what actually drives design decisions. I expect either the interviewee to ask these questions explicitly or to state their assumptions clearly and move forward. Either is fine. What matters is that assumptions are made consciously.
This is where things should start outlining themselves. The 20 ms latency requirement is tricky. Someone should immediately ask whether this is P50, P90, or P99. It matters a lot. If someone cannot think in those terms, it usually means they have not dealt with latency targets in real systems before.
For the purpose of this exercise, we did set P99 latency to 20 ms. That is a tight budget. With P99 at 20 ms, a disk first design is a risky bet. Even with fast SSDs, tail latency, queueing, and contention make it hard to keep reads consistently under budget. That pushes the primary read path toward memory, with disk used for durability in the background. I will revisit the cost trade-off later.
Once we arrive at that conclusion, the next question becomes unavoidable: how much memory do we need for 4 TB of data? That immediately leads to another question: how many machines do we need? Again, assumptions are fine here. We can say each machine has 64 GB of RAM. If someone also accounts for the operating system, background services, JVM or runtime overhead, and leaves buffer space instead of using 100 percent of memory, that is a very good sign. It shows they are not just doing math, but actually thinking about how systems behave in the real world. Now, let’s do back of the napkin calculus for the above.
Back-of-the-Napkin Calculus
We learned we need to store 4 TB of data. Let’s see how many machines we need.
Number of Machines
Now assume a machine memory size. If each machine has 64 GB RAM, we should not allocate all of it to data. Leave room:
- OS + daemons
- caches, buffers
- safety margin
A clean assumption: 50% usable for dataset. So usable RAM per machine:
- 64 GB × 0.5 = 32 GB usable
Now compute machines:
- 4 TB = 4 × 1024 GB = 4096 GB
- 4096 GB / 32 GB ≈ 128 machines
So we’re roughly in the 128 machines range. With replication factor(RF) of 3, the memory footprint requirement would be roughly 12 TB before accounting for overhead. On top of that we should budget for metadata, fragmentation, and headroom, so the real memory requirement is higher than 3x but remember we didn't use the entire memory earlier. We are using 50%. So, so for most part, that should cover it. That means the initial machine count must be scaled accordingly, and capacity planning becomes a first-class part of the design, not an afterthought. Anyway, we need somewhere around 384 machines for RF=3. Note that real count might depend on overhead/SLAB/GC/off-heap, etc.
Throughput Sanity Check
Now, 100,000 requests/sec at the API layer. With 90% reads / 10% writes:
- Reads: 90,000 Get/sec
- Writes: 10,000 Put/sec
But capacity is driven by replica work, not only client RPS. With RF=3:
- Reads: if we do quorum reads (R=2), each Get fans out to 3 replicas even if we need 2 acks because that'd help with tail latency.
- Writes: each Put is forwarded to all 3 replicas even if we only wait for W=2.
Hence, total replica ops/sec ≈ 100k x 3 = 300k. If spread across 384 machines: 300,000 / 384 ≈ ~800 ops/sec per machine. That is trivial for a CPU. CPU is not the fight here. The real challenge becomes:
- request routing and load balancing
- tail latency (P99)
- network hop cost
- hotspot keys
- replication writes
So we are not CPU-bound. We are latency-bound and distribution-bound, which is where systems get painful.
Latency Sanity Check
If we assume P99 = 20 ms, then we should budget the latency including the following factors:
- client → LB → node network time
- queueing time under load
- lookup time (in-memory)
- replication (if synchronous)
- response back
In-memory lookup is microseconds. The real cost is:
- network
- GC pauses (if managed runtime)
- queueing under bursts
- replication coordination
This pushes us toward:
- in-memory primary path
- no disk on the read path
- async disk persistence
- careful choice of consistency model
Storage Durability
We did not pin down durability during requirements gathering, which is common in interviews. That is fine. At this point, we should state an assumption and move on. Even if reads are memory first, most real systems still want a write ahead log and snapshots. The key point is that the disk is not on the read path, regardless of how we implement durability. Now, even if reads are memory-first, we likely still want:
- an append-only log per node for durability
- periodic snapshotting
- WAL replay on restart
It's a good time to check in with the interviewer to see if they want us to think about this. Or we can tell this is something we’d deal with later. But the key point is the following. The disk is not in the P99 read path regardless of how we solve durability.
Architecture Decisions
Now we turn the requirements and the back-of-the-napkin math into concrete design choices. This is the part where the system stops being abstract and starts having an opinion, and we own the trade-offs..
Region and Failure Domain
Given P99 = 20 ms, the default assumption is:
- single region
- multi-az for fault tolerance
We should check this with the interviewer again but chances of them asking for multi region replication is low but you never know. If we go multi-region, the problem changes completely. Latency budgets, replication, conflict resolution, client routing, everything becomes a different conversation.
Service Discovery and Routing
This is one of the important architecture decisions, and it must be explicit. Otherwise the design is incomplete. There are two common approaches we can take here.
Client Side Routing
Clients use a library that knows cluster membership and partitioning. They compute hash(key) and talk directly to the correct nodes.
- Pros: fewer hops, better for P99
- Cons: client library complexity, versioning, stale membership, harder for multi-language environments
Server Side Routing
Clients send requests to a stable endpoint, and the system routes internally. For this exercise, I prefer this option because it keeps clients simple and keeps the system evolvable. Client libraries become a pain in the ass fast because of maintenance burden, especially across multiple languages and deployment cadences.
- Clients talk to kv.yourdomain.com
- DNS points to a load balancer
- LB forwards to any node acting as a coordinator
- The coordinator computes shard placement and forwards to the right replicas
This adds an extra hop, but it is usually worth it. Fewer client fires later.
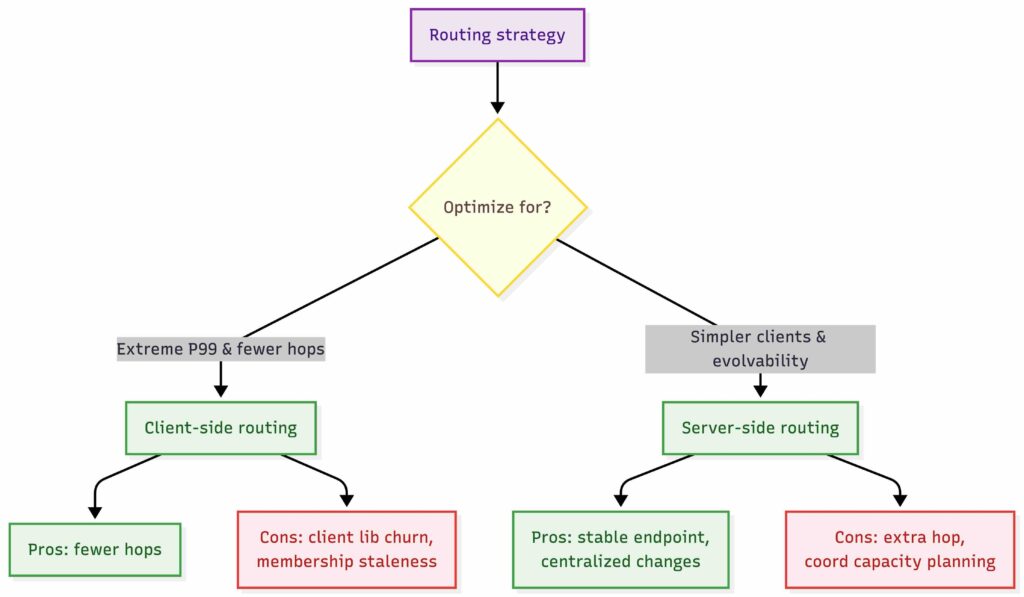 Key Value Store Routing Strategy
Key Value Store Routing Strategy
Coordinator Availability
Coordinators are stateless. They only hold transient request state. This means:
- Any node can act as a coordinator
- If a coordinator fails mid-request, the client retries via the load balancer and gets a different coordinator
- No special replication or leader election needed for coordinators
The LB performs health checks (TCP or HTTP /health endpoint) and removes unresponsive coordinators from rotation within seconds.
Partitioning Strategy
We need to spread 4 TB of data across many machines, and we only have key-based access patterns. So the default:
- Consistent hashing on key
- Each node owns a range of tokens (a slice of the hash ring)
This makes adding or removing nodes manageable, and it pairs naturally with replication. Range partitioning can be fine too, but we do not have scans, and range adds complexity for little gain here.
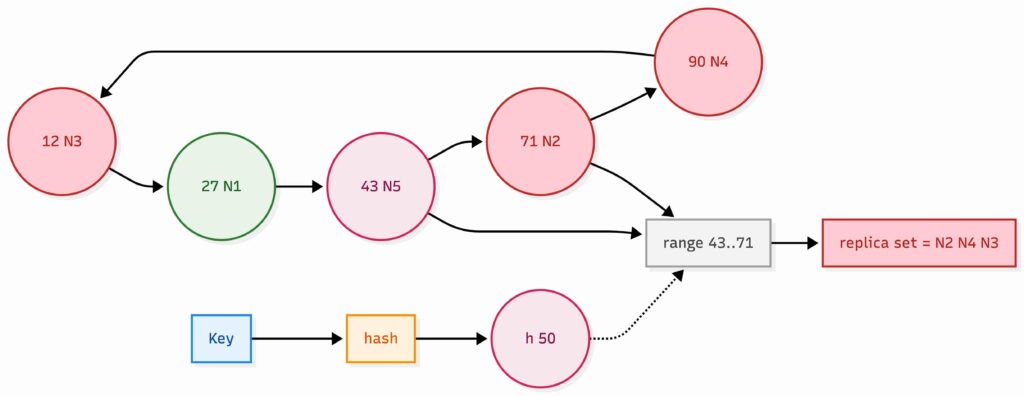 Consistent hashing ring with five nodes and replication factor 3
Consistent hashing ring with five nodes and replication factor 3
Replication and Consistency
Another requirement we missed, consistency. This is normal, but you cannot dodge it. We never clarified consistency requirements, which is normal in interviews. A good candidate either asks, or states assumptions. So, we tell our interviewer. We decided to go with RF=3, so we might as well spread these replicas across AZs to decrease the likelihood of losing all replicas for an entire partition if we lose an AZ.
Then we choose read/write quorums:
- Write quorum W = 2
- Read quorum R = 2
With RF=3, R+W > RF gives us strong-ish guarantees against stale reads under normal operation, but it can add tail latency under certain failure or congestion patterns. If we attach a version to each value and the coordinator returns the highest version it sees, then a quorum read after a completed quorum write will not return an older version, assuming the coordinator talks to a real quorum (no “sloppy quorum”) and replicas respond honestly.
This still does not give linearizability. Linearizability requires a single ordered history, usually via consensus (Raft/Paxos) per partition. Quorums give you strong convergence properties and good practical freshness, but under concurrent writes you can still observe races and conflicts unless you add a stronger ordering mechanism.
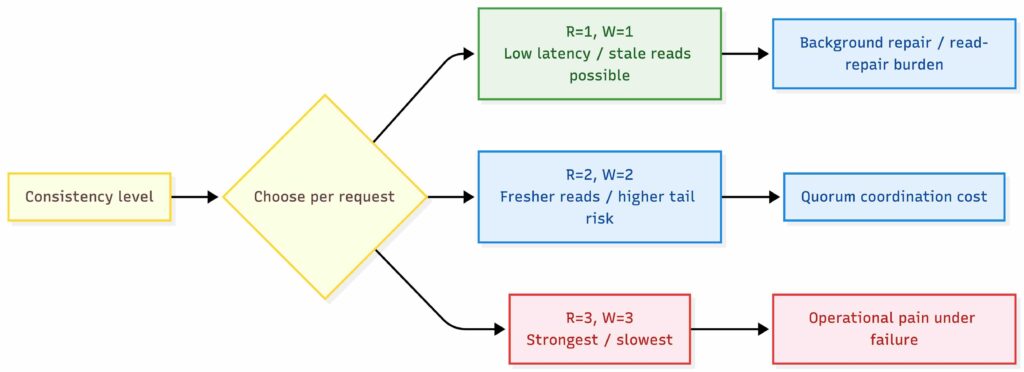 Key Value Store Read Write Consistency
Key Value Store Read Write Consistency
Conflict Resolution
With eventual consistency or during network partitions, two clients might write different values for the same key to different replicas. We need a deterministic merge strategy:
- Last-write-wins (LWW): Store (value, version) and let the highest version win during reconciliation. The key is what version means. If you use raw wall-clock time, you can lose writes under clock skew, because a later write might receive a smaller timestamp and get overwritten during merge. A pragmatic approach is to treat the version as a timestamp-like value generated at write time (by the client or the coordinator), then make convergence deterministic with a tie-breaker when versions collide (for example, deletes win, otherwise compare a stable (version, node_id) ordering). This keeps the model simple and makes replica reconciliation straightforward, with an explicit trade-off: concurrent writes to the same key are not linearizable, and one of them can be dropped under LWW.
- Vector clocks: Track causality across nodes. Detect true conflicts and either merge automatically or surface to the application. More complex but more correct.
For many key/value workloads, LWW with a safer versioning scheme (HLC or per-partition monotonic versions) is the pragmatic choice.
Hinted Handoff
If a replica is temporarily unreachable during a write, the coordinator stores the write as a "hint" locally. When the replica recovers, the hint is replayed. This improves write availability during transient failures. If we want a true stateless coordinator, we should not have this. A hint obviously introduces state. Let's mention it but we won't implement it. It also introduces a few risks:
- Hints consume disk space if a node is down for a long time
- Hint replay creates a burst of traffic on recovery
Storage Model
In this design, we won't have the disk in the read path to keep tail latency predictable. If cost becomes an issue, we’d think about SSD/NVMe with a hot set in memory. With that in my mind, we end up with:
- In-memory map for serving reads fast
- Write-ahead log (WAL) for durability (sequential append)
- Periodic snapshots to reduce replay time
In-Memory Data Structure
The simplest choice is a concurrent hash map (e.g., ConcurrentHashMap in Java, or a lock-striped hash table). This gives O(1) lookups and works well for point queries.
Considerations:
- Memory fragmentation: Long-running processes with many updates can fragment the heap. Consider pre-allocation or off-heap storage for very large datasets.
- GC pressure: Managed runtimes (JVM, Go) will pause for garbage collection. Tune GC carefully, or consider off-heap storage with manual memory management.
Snapshot Strategy
Periodic snapshots reduce WAL replay time on restart. Key decisions:
- Full vs. incremental: Full snapshots are simpler but larger. Incremental snapshots (only changed keys since last snapshot) reduce I/O but complicate recovery.
- Consistency during snapshot: Use copy-on-write / MVCC (or a brief pointer/epoch capture) so snapshotting doesn’t stall writes. Blocking writes during a snapshot is unacceptable for our latency target.
- Snapshot frequency: Balance between snapshot I/O overhead and WAL replay time. A reasonable default: snapshot every 15–30 minutes, or when WAL exceeds a size threshold.
For 32 GB of data per node, a full snapshot to local SSD takes roughly a few minutes at typical disk speeds. This is the simplest shape that still survives restarts.
Read path
Using server-side routing:
- Client calls Get(key) via load balancer
- Coordinator hashes key and finds replica set
- Coordinator queries replicas and returns value
Typical choice:
- send to R replicas and return the newest / first valid response, depending on the consistency model
This is where we can later discuss:
- hedged reads for tail latency
- hotspot handling
- caching
But the baseline is already clear.
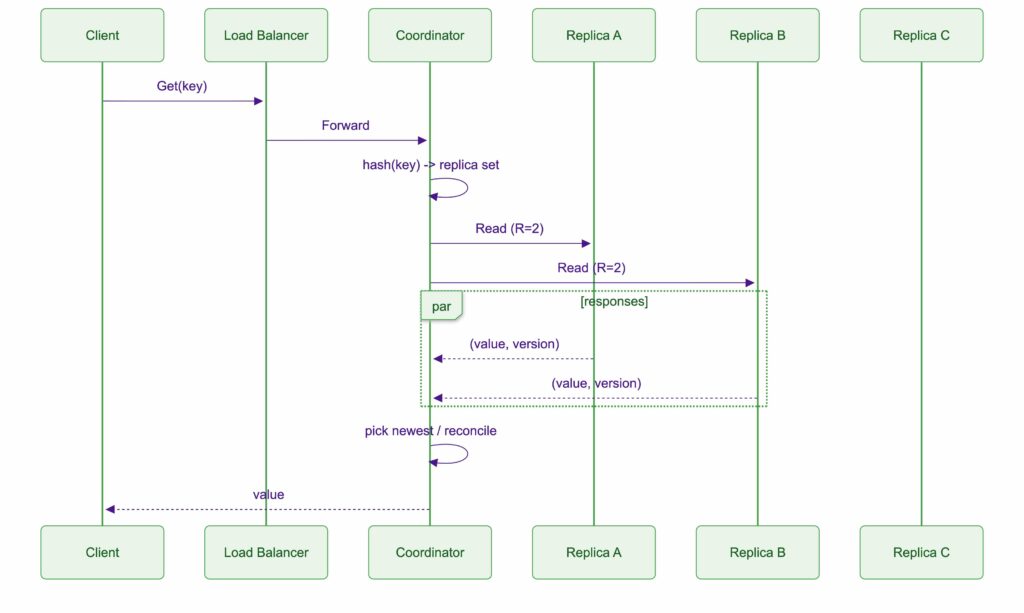 Key Value Store Read Path Sequence Diagram
Key Value Store Read Path Sequence Diagram
Write Path
- Client calls Put(key, value) via load balancer
- Coordinator hashes key and finds replica set
- Coordinator forwards to replicas
- Each replica:
- appends the mutation to the WAL
- applies the mutation to the in-memory map,
- acks the coordinator,
- flushes WAL to disk using group commit (e.g., fsync every second, or when the WAL buffer reaches a threshold)
- Coordinator returns success after W acknowledgements
This means an acknowledgement does not necessarily mean durable on disk. It means “replicated to W replicas in memory”, with disk lagging behind by a small window. This buys tail latency, at the cost of potentially losing the last few seconds of writes if enough replicas crash before flushing. Disk exists, but only as a sequential log and snapshot backing. Reads stay in memory.
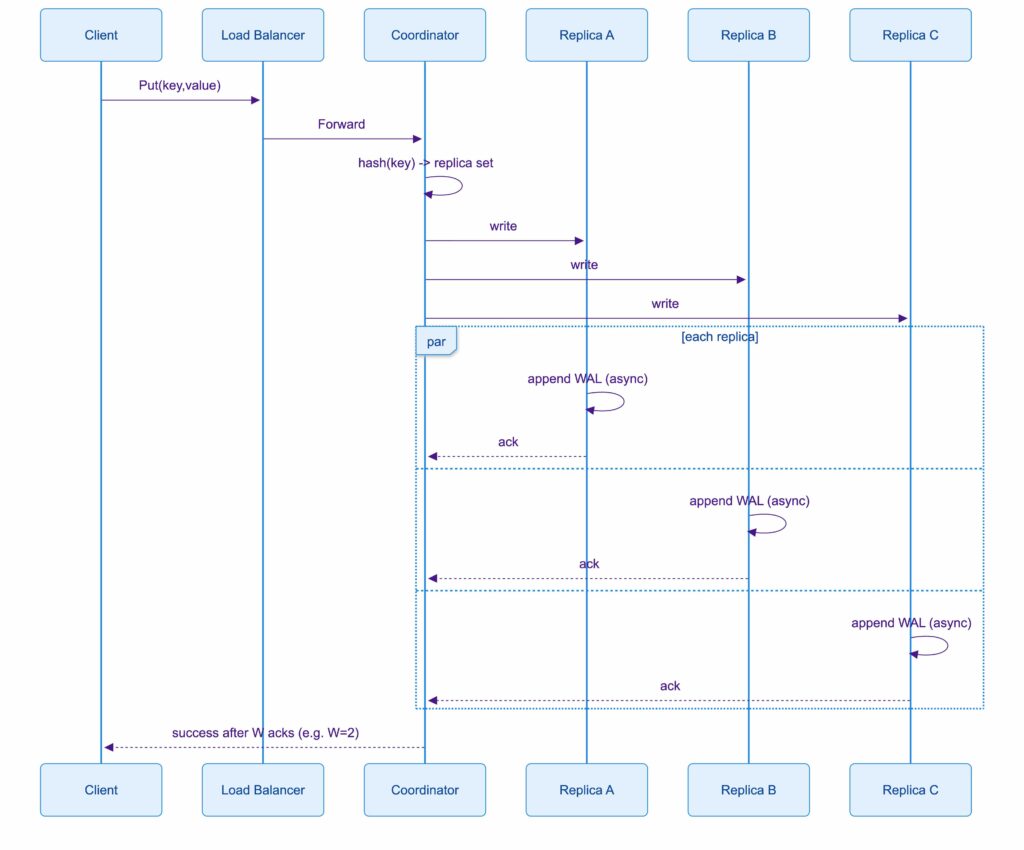 Key Value Store Write Path Sequence
Key Value Store Write Path Sequence
Membership and Rebalancing
If nodes can act as coordinators, they need a shared view of the cluster:
- nodes maintain membership e.g who is in the cluster
- partition ownership comes from the hash ring
- when nodes join/leave, data is rebalanced
- background repair keeps RF satisfied
The load balancer only needs health information to send requests to any healthy coordinator. Cluster membership and partition ownership are maintained by the nodes themselves (for example via gossip plus an epoch, or via a small strongly consistent control plane such as etcd/Consul/ZooKeeper).Let’s go with gossip for membership and liveness, because it keeps the system dependency-light. But for partition ownership changes e.g. ring epoch, we still need a conservative way to advance epochs so different coordinators do not invent conflicting ownership. Thus, we need a ring epoch advancement gated by a small quorum among current owners.
 Key Value Store Membership
Key Value Store Membership
Rebalancing Mechanics
When a node joins or leaves, the hash ring changes and some keys move to new owners. This must happen without violating availability or consistency.
- Streaming: The old owner streams data to the new owner in the background. Reads continue from the old owner until streaming completes.
- Handoff: Once streaming reaches a safe point, the system advances partition ownership using a ring epoch.
- Throttling: Rebalancing consumes CPU and network. Throttle to avoid impacting foreground latency.
During rebalance, requests for in-transit keys may have slightly higher latency due to coordination between old and new owners.
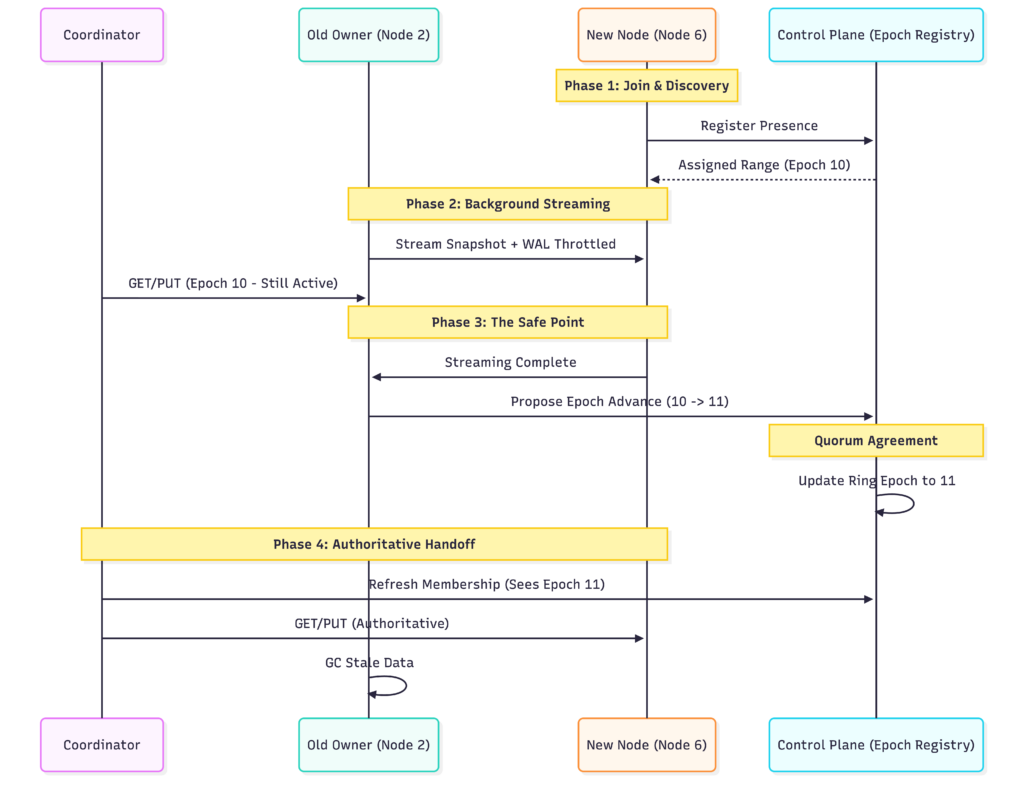 Key Value Store Membership Sequence
Key Value Store Membership Sequence
Forcing Trade-offs
We now have a decent solution in place. Remember that we didn’t draw anything. Well, we don’t even need that. Conversation and things we have considered already outlines how we’ll work this through. Now, if someone got this far, this is already good but let’s push them to make a few more trade offs.
A lot of people try to keep everything: P99 20 ms, durability, strong consistency, multi-AZ, simple clients, cheap infrastructure. We cannot have all of it. At some point we must choose which constraints win.
 Key-value store system design
Key-value store system design
Latency vs Consistency
We already hinted this off, right? If we truly mean P99 = 20 ms, then quorum reads and writes can get uncomfortable fast during:
- noisy neighbors,
- transient network jitter,
- GC pauses,
- AZ-level congestion,
- partial failures.
So the trade-off becomes explicit:
- Quorum (R=2, W=2) gives us better consistency but increases tail latency risk.
- Eventual consistency (R=1, W=1) makes latency easier but allows stale reads.
- And somebody needs to fix those inconsistencies, a background job of some sort
A strong answer is not “quorum is best” or “eventual is best”. A strong answer is: make it tunable. Let the caller choose per request. Let them pick their poison.
- default to quorum for correctness-sensitive operations,
- allow faster consistency levels for less critical reads.
Latency vs Durability
If you require that every write is durable before acknowledging, we need WAL fsync behavior that can hurt tail latency. But we also said we could relax this a bit. So we can choose async. It gives us better latency but the risk of losing recent writes on crash.
Most real systems pick a middle ground:
- group commit (batch fsync),
- configurable durability,
- or acknowledge after memory + replication, and let the disk lag slightly.
We have to say what we are doing, because the system behaves very differently.
Simple clients vs Fewer hops
Client routing is the same kind of trade-off:
- Smart clients reduce hops and can help P99, but they increase engineering and operational burden.
- Routing tier / coordinators simplify clients, but add a hop and can become a bottleneck if designed poorly.
If you’re optimizing for interview clarity, the routing tier is fine as we chose earlier. If we’re optimizing for extreme P99, smart clients start looking attractive. We need to say why this is operationally harder. Well, keeping the library up to date, seed node change, deployments to a name a few.
Cost vs Availability
Replication factor drives both durability and cost.
- RF=3 across AZs is the safe default, but triples storage and multiplies network work.
- RF=2 is cheaper but creates awkward edge cases under failure.
- RF=1 is basically not a production store unless it’s backed up by something else.
This is also where people forget that memory is expensive. If we truly keep everything in memory, RF=3 is not “just 3 copies”, it’s 3 x RAM. So you can’t avoid the question: how much are you willing to pay for availability? If someone doesn’t think about cost, that’s a red flag. Frugality drives creativity.
Hot Keys vs Simplicity
Consistent hashing assumes that keys are roughly uniform. Reality rarely is. A single hot key can melt one shard and blow your P99 even if the rest of the system is completely idle.
At that point, you have a choice. You either keep the design simple and accept the risk of hotspots, or you introduce additional complexity to absorb skew. This is generally my follow-up question in interviews. People often struggle here, not because the techniques are exotic, but because they have not seen this failure mode in practice. There are a few common ways to deal with hot keys.
Caching
If the hot key is read-heavy, caching is usually the first and cheapest win, but it must be explicit about staleness. A coordinator can cache (value, version) for a short window and serve reads locally. On cache hit, it can either:
- accept bounded staleness (time-based TTL on the cache entry), or
- validate freshness by occasionally sampling a replica for the latest version, or
- subscribe to invalidations (more complex).
Without one of these, coordinator caching can silently become an unbounded stale-read bug.
Request coalescing
When many identical requests for the same key arrive at the same coordinator at roughly the same time, the coordinator can collapse them into a single in-flight request to the replica set. One backend fetches fans out to many waiting callers. In our design, this happens entirely at the coordinator layer and helps prevent burst traffic from overwhelming a single shard. The risk is that a slow backend response now delays many requests at once.
Partition Splitting
If a single key or a very small key range dominates traffic, hashing alone is no longer enough. In our design, this can mean logically splitting the key into sub-partitions and mapping them to different token ranges, even if they ultimately represent the same conceptual value. This pushes complexity into routing, rebalancing, and recovery, but it is sometimes the only way to scale extreme hotspots. Splitting ranges also increases the amount of metadata the system needs to manage and makes failure handling less trivial.
Special handling for hot keys
Sometimes the cleanest solution is to admit that a key is special. Pretending everything is uniform is how you get surprised in production. The coordinator detects hot keys dynamically and routes them through a separate code path, with more aggressive caching, higher effective replication, or dedicated resources. This breaks the uniformity of the system, but uniformity is already broken by the workload.
Each of these techniques trades simplicity for resilience under skew. None of them are required for a toy design. Almost all of them eventually appear in production systems.
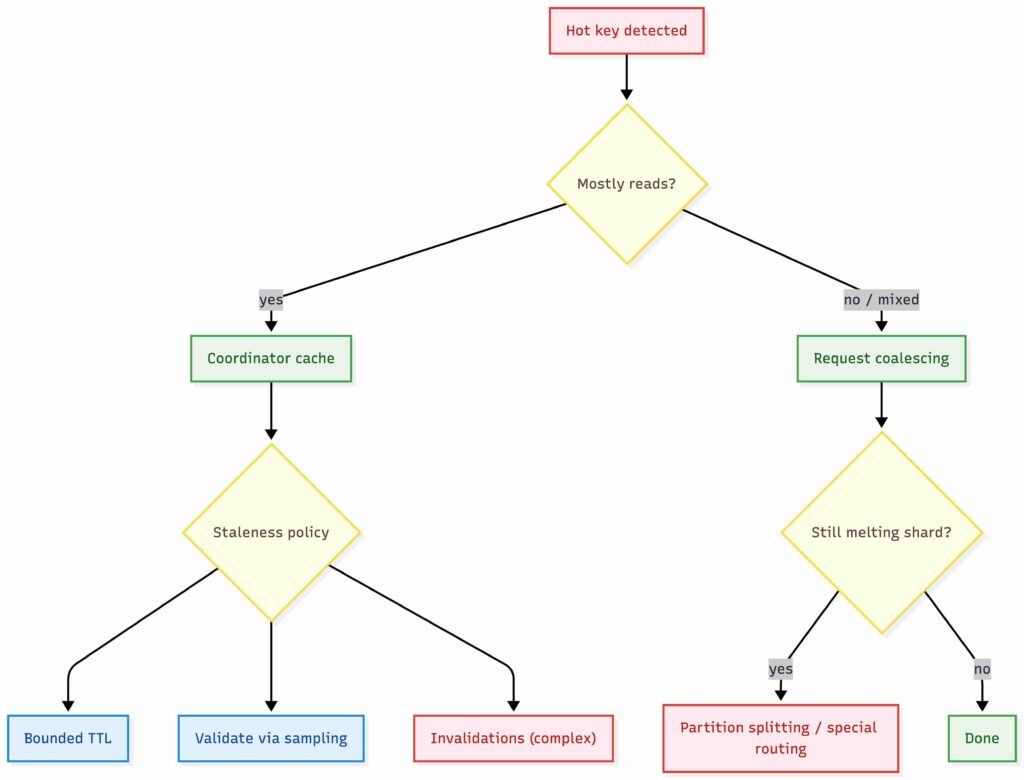 Key Value Store Hot Key Handling
Key Value Store Hot Key Handling
Memory Density vs Operational Complexity
Our node count here is dictated by memory density, not CPU throughput. With the current assumptions, each node only handles a few hundred ops/sec, which is low. The cluster looks big because we are buying RAM with node count. In a real build, we would likely choose larger instances (for example 256 GB RAM per node) to reduce node count significantly, which simplifies gossip, failure churn, rebalancing, and overall ops overhead.
Cost vs Predictability
I have chosen an all-RAM primary read path to make the tail predictable under a strict 10–20 ms P99 target. I fully acknowledge that at this scale, RAM is dramatically more expensive than using fast SSDs or NVMe. Those devices can deliver excellent latency, but in a production KV store the storage engine introduces its own overhead (compaction, write amplification, queueing under bursts), and that is often where tail latency gets difficult. If cost became the priority, the design would pivot to SSD/NVMe-backed storage with an in-memory hot set, while keeping the same partitioning, replication, and consistency model.
Failure Scenarios
Designing the happy path is easy. The real system is what happens when everything starts going sideways. You see shit happens at 03:00 when a node dies, a disk fills, or an AZ gets weird, and you are the one getting paged. That is the whole point. From an operational perspective, you want two things:
- predictable behavior under failure
- boring, repeatable recovery workflows
Below is how I like to frame it for a key/value store.
Single Node Failure
What happens
- One node stops responding or gets partitioned.
- Some token ranges lose a replica.
Expected system behavior
- Reads and writes continue as long as quorum is still reachable (if using quorum).
- Coordinators mark the node unhealthy and stop routing traffic to it.
- The cluster enters a “degraded replication” state for the affected ranges.
Operational workflow: node replacement
- Treat nodes as cattle, not pets.
- Bring up a new node with the same configuration and let it bootstrap.
- Bootstrap means: join membership, get assigned token ranges, then stream data from existing replicas.
- Once bootstrap completes, the old node can be permanently removed.
Key operational decision
- Do you allow automatic re-replication immediately, or do you wait for a grace period in case the node comes back?
- Immediate repair is safer for durability but creates load spikes. Grace periods reduce churn but increase the risk window.
Disk failure or WAL corruption
Even though reads are memory-first, you still rely on disk for WAL + snapshots.
What happens
- Disk goes read-only, fills up, or starts throwing IO errors.
- WAL appends fail, snapshot writes fail, restart recovery becomes unsafe.
Expected system behavior
- The node should self-demote quickly. If it cannot persist, it should not accept writes.
- Coordinators should treat it as unhealthy and route around it.
- Alerts should fire before this becomes an outage.
Operational workflow
- Replace the node, not the disk.
- New node bootstraps and streams data.
- The broken node is removed and investigated offline.
Practical detail
- Most real incidents here are not “disk died”, it’s “disk full”.
- WAL growth without compaction, snapshot failures, or logs filling the volume will take you down the same way.
Node restart and Cold start
In-memory systems fail in a very specific way: restart means empty memory.
What happens
- Node restarts, memory is empty.
- Node replays WAL and/or loads snapshot.
- Depending on data size, replay can be slow and unpredictable.
Expected system behavior
- Node should join as non-serving until it is safe.
- It should only begin serving once it reaches a defined readiness gate:
- snapshot loaded,
- WAL replayed up to a point,
- and membership has converged.
Operational workflow
- Rolling restarts must be safe:
- never restart too many replicas for the same token ranges at once
- enforce restart budgets per AZ
Key operational decision
- Snapshots must be frequent enough that WAL replay time is bounded.
- Otherwise, your recovery time becomes “how long since last snapshot”, which is not an SLO, it is a gamble.
AZ Failure
This is the failure mode that turns replication factor into a real deal.
What happens
- One AZ is partially or fully unreachable.
- Some replicas disappear at once.
Expected system behavior
- If replicas are spread across AZs, the system should continue serving with reduced redundancy.
- If quorum is required, you need to ensure quorum still works with an AZ down. With RF=3 across 3 AZs, losing one AZ still leaves 2 replicas, so quorum can still be satisfied.
Operational workflow
- The cluster should not immediately try to re-replicate everything into the remaining AZs.
- Moving terabytes of data consumes massive network bandwidth and CPU.
- If the AZ comes back online in 10 minutes (e.g., a switch reboot), you have wasted resources and potentially caused congestion.
- Policy: Wait for a stabilization period (e.g., 60 minutes) before declaring the replicas lost and triggering a rebuild.
- Operators need visibility into:
- How many partitions are under-replicated.
- How close the cluster is to losing quorum for any specific range.
Network partition and Partial failure
This is the classic “some nodes are reachable, some are not” situation.
What happens
- Coordinators see different membership views.
- Some writers reach some replicas but not others.
- Tail latency spikes due to retries and timeouts.
Expected system behavior
- Membership changes should be conservative.
- Coordinators should use aggressive timeouts and retry logic, but not in a way that creates a retry storm.
Operational workflow
- You need clear dashboards and a known playbook:
- Is this a client-side issue, LB issue, node issue, or network issue?
- Is it one shard range, one AZ, or systemic?
This is also where your consistency model matters. Under partition, you either:
- reject writes to preserve correctness,
- or accept writes and resolve conflicts later.
There is no free option. You either pay now or you pay later.
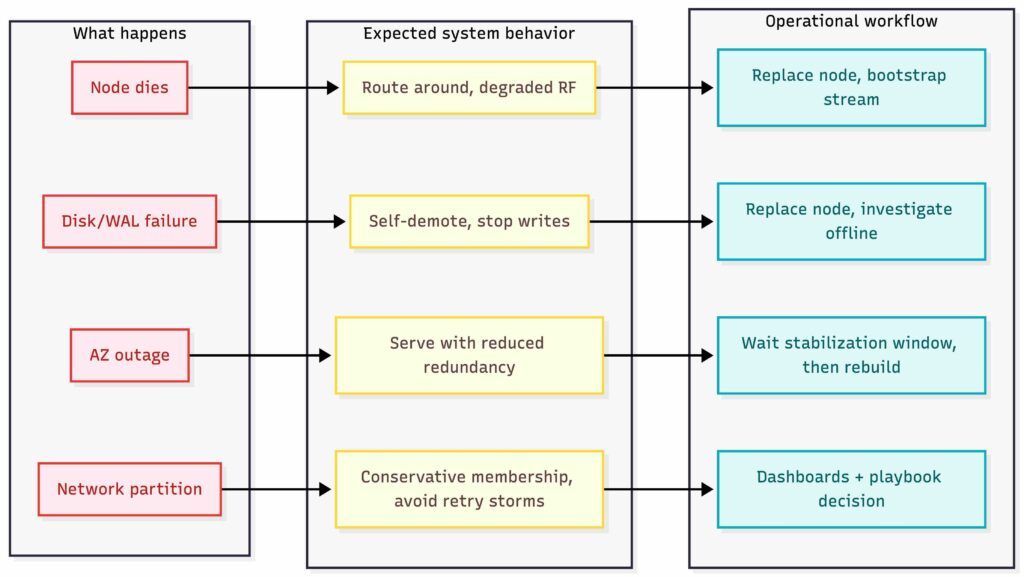 Key Value Store Failure Scenarios
Key Value Store Failure Scenarios
Operational Excellence
Let us call out the operational basics. A design that looks clean on a whiteboard but falls apart on call is not a real design. If I were on call for this system, I would want three dashboard groups from day one.
User-Facing Health
- Request rate and concurrency, split by Get and Put, plus a breakdown by keyspace or partition to catch skew.
- Latency percentiles, at minimum P50, P95, P99, P99.9, tracked separately for Get and Put, with clear SLO overlays.
- Error rate by class, including timeouts, quorum failures, overload rejections, and client-side errors, because each points to a different failure mode.
Data Safety and Replication Health
- Under-replicated partitions, with an explicit view of “time to quorum risk” for any range.
- Read and write quorum failures, split by cause, such as missing replicas, slow replicas, or coordinator timeouts.
- Repair health, including repair backlog, hinted handoff backlog, and indicators of replica divergence.
- Recovery readiness, measured through snapshot age, snapshot success rate, WAL size growth, and estimated WAL replay time, since this controls restart and rebuild risk.
Saturation and Bottlenecks
- Queueing and tail amplification, especially coordinator queues, per-hop latency, and long-tail contributors.
- Compute and memory pressure, including CPU saturation, memory pressure, garbage collection behavior, and allocator churn.
- Network limits, including cross-node bandwidth, retransmits, and saturation at the NIC level.
- Disk signals for durability paths, including disk fullness, fsync latency, and WAL write latency, even if the disk is not on the read path.
Alerting should follow the same hierarchy. Page when user-facing SLOs burn fast, such as P99 latency or error spikes. Page when data safety is at risk, such as under-replication, rising quorum failures, or diverging replicas. Warn on saturation early, before it becomes user-visible and starts compounding.
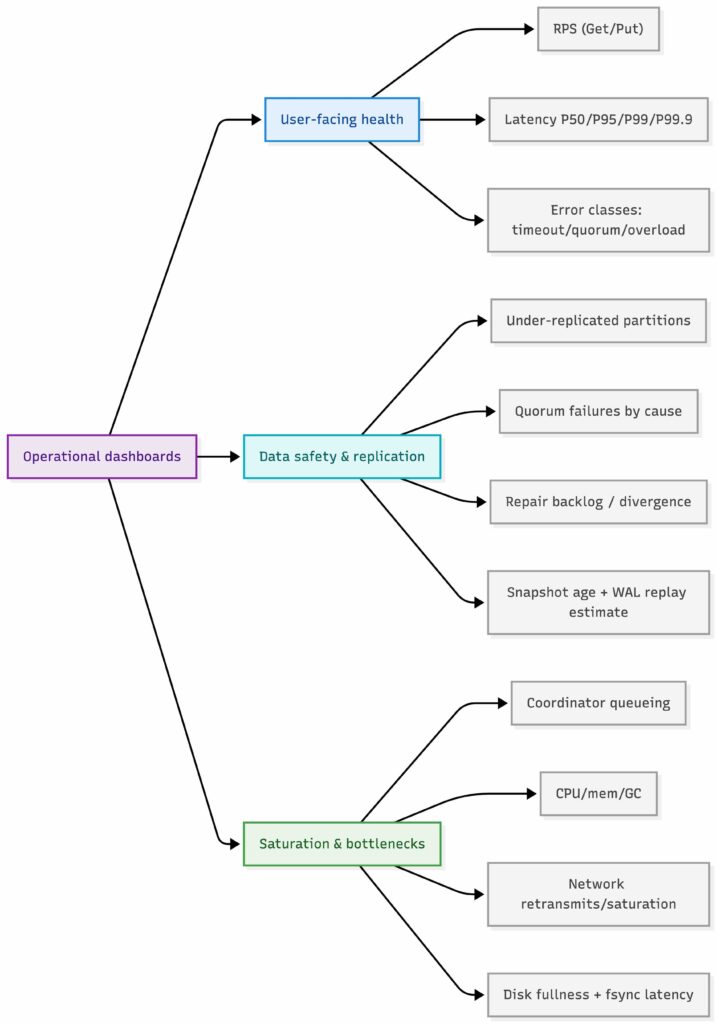 Key Value Store Operational Dashboards
Key Value Store Operational Dashboards
Rollout Plan
This sort of distributed system design that cannot be rolled out easily. For a distributed system, rollout starts before production with a repeatable way to test correctness and to rehearse failures, not with a big bang deploy.
Phase 0: Build the Safety Net
Before scaling anything, I want a small “test harness” that can:
- generate realistic concurrent traffic patterns,
- record what happened,
- and replay the same scenarios again and again.
Most importantly, it must let us simulate the failures we know we will see in real life:
- a node dying,
- a disk filling up or becoming slow,
- an availability zone going away,
- and network trouble, delay, packet loss, or partitions.
The goal is not to be fancy. The goal is to make failures boring and repeatable.
Phase 1: Prove the Core Loop
- Start with a single-node prototype, correctness first.
- Add basic WAL and snapshots, and validate restart recovery.
- Measure tail latency early, because P99 is where distributed systems hide their pain.
Phase 2: Small Cluster in a Non-Prod Environment
- Run a 3–5 node cluster across failure domains if possible.
- Keep the same test harness running continuously.
- Inject failures on purpose and confirm the system behaves as expected.
- Validate membership convergence, bootstrap, rebalancing, and repair workflows.
Phase 3: Shadow Traffic
- Mirror reads, and optionally dual-write, from a real service, while keeping the source of truth unchanged.
- Compare responses and latency distributions, not only averages.
- Treat mismatches as correctness issues until proven otherwise.
Phase 4: Canary
- Route a small percentage of production traffic to the new store.
- Gate the rollout on clear signals: P99 latency, error rate, quorum failures, and replication health.
- Keep an instant kill switch: revert routing back to the old path, or force read-only mode if safety is at risk.
Phase 5: Expand Gradually
- Increase traffic in steps, onboard services one by one.
- Run load tests and failure rehearsals before each expansion step, not after.
- Only declare “done” once on call has runbooks, dashboards, and known recovery workflows.
This is the difference between shipping value step by step and gambling on a big bang.
 Key Value Store Rollout Plan
Key Value Store Rollout Plan
Wrapping it Up
Now, going through all of this, you probably started to appreciate how involved this problem can become. What looks like a simple key/value store on the surface quickly turns into a conversation about latency, memory, consistency, routing, operations, failure modes, rollouts and so forth. And you know what, I did not cover it all. You probably noticed many parts I missed or intentionally didn’t cover.
What did we gain out of this? Well, if you can reason about this problem end to end, you are very likely able to reason about many other system design problems as well. The mechanics change, but the way of thinking remains the same. It is not about memorizing the "right" architecture, but about identifying constraints, asking the right questions, and making intentional trade-offs.
One thing we did not cover here is queueing. You often need it for many distributed workloads, especially when smoothing bursts, protecting downstream systems, or enforcing fairness. In this particular design, we did not strictly need it, but knowing when not to introduce a queue is just as important as knowing when to use one.
Even without that, we touched on a lot of ground: requirement shaping, back-of-the-napkin math, architecture decisions, forced trade-offs, and operational realities. That is exactly why I like this question so much. It is simple to state, hard as hell to get right, and very revealing of how someone actually thinks about building systems.