While working on my book on big data platforms, I keep noticing the same pattern. Some systems look simple while they belong to one team and become something else after everybody starts using them. Message brokers are one of those systems.
One of the teams start using RabbitMQ to push work into the background. Another team drops in Kafka to feed a data pipeline. Both decisions can make the system cleaner. The request path gets shorter. Slow work moves off the critical path. A consumer can go down without dragging the producer with it. Good trade-offs. Voila!
The trouble starts later. When the broker becomes the place where every team parks whatever it does not want to handle synchronusly.
Local Broker is Easy Peasy
When one team owns the producer and owns the consumer, they understand why the message exists, what it means, how often it arrives, what happens if processing fails, and whether an old message is still useful tomorrow. If the queue fills, the team knows which workflow is stuck. If a message lands in a dead letter queue, someone knows whether it is safe to replay, drop, or repair. If retry logic starts hammering a database, the team can change both sides of the flow.
The broker is still infrastructure, but it is not yet shared infrastructure. The blast radius is small enough that the people creating the load are close to the people paying for it.
Shared brokers change that. If Kafka or RabbitMQ becomes a shared infrastructure capability, your broker starts carrying traffic from teams with very different habits and needs. Some workloads are steady. Some arrive in spikes. Some need ordering. Some need replay. Some need low latency. Some need long retention. Some are written by people who deeply understand the broker. Some are written by people who only know that there is a client library and a topic name.
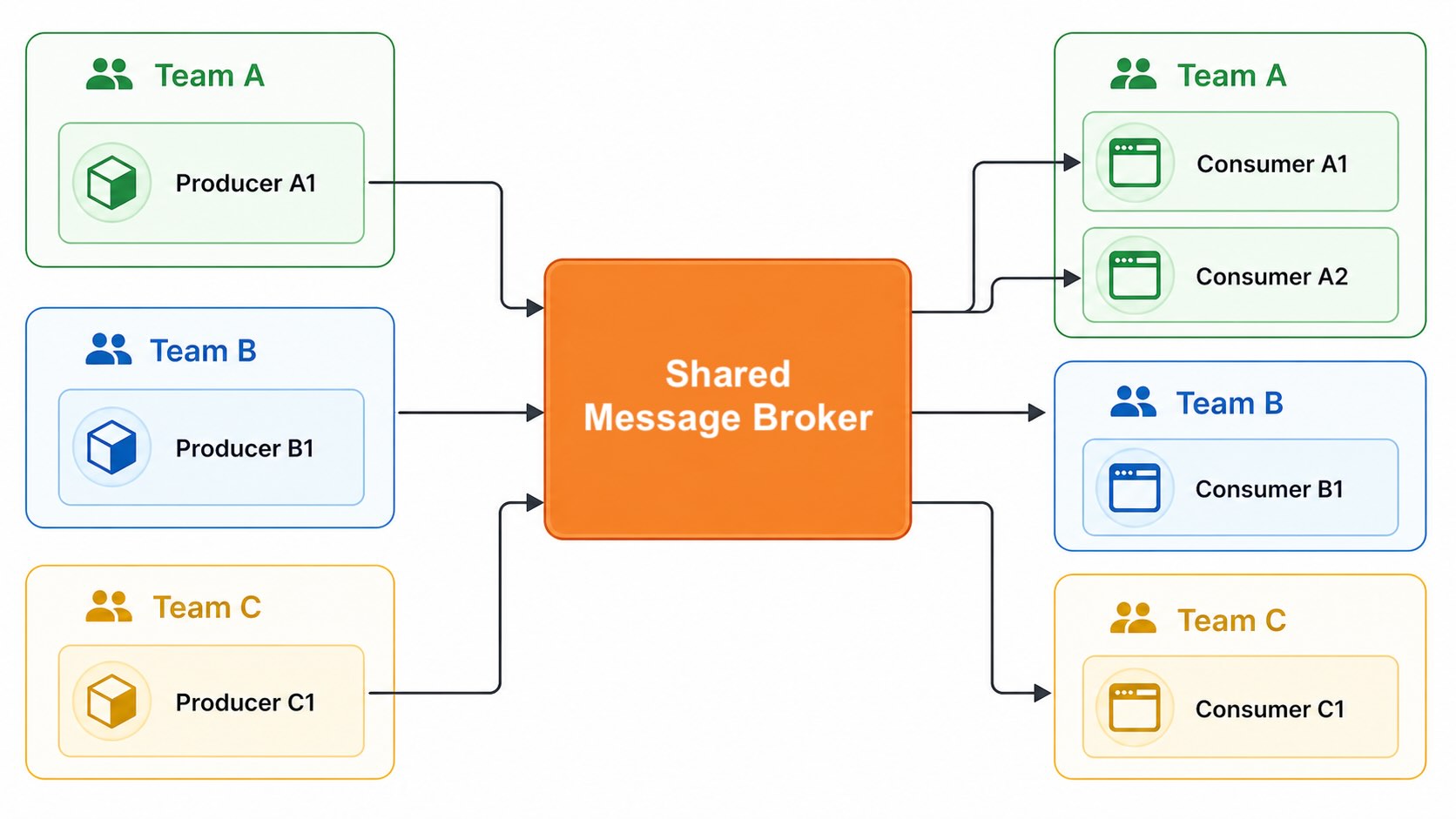 Shared Message Broker
Shared Message Broker
Average Load Is Useless
A lot of bad messaging designs look fine when you talk about average throughput. The system handles 10,000 messages per second. Then one team replays old data. That load is different from live traffic. Kafka is very good at serving consumers near the tail of the log because the data is often hot in page cache. A consumer that goes far back into old offsets can force disk reads, push out hot data, and create latency for other tenants on the same brokers. The team doing the replay may think they are running a local recovery. The other teams only see their consumers getting slower for no obvious reason.
That is a grid problem. One team plugged in a heavy load and the lights flickered somewhere else. This is why “Kafka can handle the throughput” is not enough. The question is what kind of throughput, from whom, at what time, on which brokers, with what retention, with which consumers, and what happens when the traffic shape changes.
A broker does not fail only because the total number is too large. It often fails because the shape of the load changed and nobody treated that as a design input.
Partitioning is Wiring
Kafka makes some early decisions that are painful later like spicy food. The partition key is the best example. It looks like a field in a producer configuration. It is closer to wiring. It decides where ordering exists. It decides how load spreads. It decides how much parallelism consumers can get. It decides which broker takes the heat.
If you pick a low-cardinality key, you can create hot partitions. If you pick a tenant as an identifier, your largest tenant may become your largest circuit. If you pick a random key, you may get a better distribution while losing the ordering of a downstream workflow. Increasing the partition count later is obviously not cake.
This is why Kafka is dangerous in a very specific way. It is excellent at preserving a log. It also preserves the consequences of decisions made before you. That does not mean Kafka is bad. It means Kafka remembers. If the partitioning model is wrong, the broker will not let that slide.
Backlog is Stored Load
Queues make overload more chill. A synchronous system fails in your face. The request times out. Users immediately start seeing errors. On the flip side, the producer publishes the message and moves on. The API returns quickly. Looks good to the producer but work might be waiting somewhere indefinitely.
That is useful. It is also how teams lie to themselves. Consumer lag is accepted work that has not finished yet. If consumers fall behind for one hour, recovery will be painful. The system now has to process live traffic plus the backlog. To catch up quickly, it needs spare capacity above normal load. Without that headroom, the backlog becomes a kind of thing you don’t want for your enemy.
Kafka and RabbitMQ fail differently here. Kafka can hold large backlogs if the disks are planned for it, but old reads can change the broker’s I/O profile and hurt other workloads. RabbitMQ behaves differently. A large backlog can hit memory pressure, block publishers, and push failure back into upstream services.
Replay is A Surge
Replay is one of the reasons I love Kafka. You can reset offsets. You can rebuild a view. You can recover from a bad consumer. You can process history again with better code. That sounds wonderful on paper. It often is.
But replay is not a harmless read. In a real system, replay pushes old load through current code. If the consumer calls a database, cache, payment provider, email provider, search system, or partner API, the replay is now loading against those systems too.
Consumers that enrich messages by calling external systems like relational databases, caches, and document stores have a hidden problem. Under replay or a traffic surge, the broker can deliver data faster than those systems can tolerate. You end up scaling up mostly to absorb I/O wait, not to do any real work. It is a lousy place to be. The broker can be fast enough to hurt you.
One Grid Creates Tool Gravity
When a company has a shared broker, people start using it for things it was not designed to do. This is normal. It is just convenient. The platform already exists. The client libraries exist. The operational team exists. Security has approved it. The dashboards exist. Someone says, “Why add another queue? Just use Kafka.”
That can be fine until Kafka becomes a task queue, a log and a bunch of other things. A slow or poisoned message can block progress for the partition behind it. You can build around this, but now you are building machinery that another tool like RabbitMQ gives you more naturally.
This is one of the stranger failure modes of platforms. A successful platform attracts misuse. People do not misuse it because they hate architecture. They misuse it because the approved path is cheaper than the correct path.
The Grid Needs Breakers
A shared broker needs limits earlier than you think it needs them, and those limits need to be stricter than feels comfortable to enforce. At first, my instinct was to enable self-service and trust teams to configure things sensibly. Unfortunately, engineers create topics without knowing which cluster has capacity to spare, default to infinite retention because history might matter someday, and assign partitions without thinking about cardinality. Each decision looks completely reasonable in isolation. In shared infrastructure, you see I/O saturation nobody can explain because the cause is spread across a dozen teams who each did something defensible. True self-service requires running guardrails automatically based on use cases. I even think schema validation has to be part of the whole thing. You should't let people mess around with data.
For instance, replay needs explicit approval. You can’t let someone hose other teams’ workloads. When a consumer goes deep into old offsets, the broker fetches from disk instead of the page cache, evicting hot data for every other tenant on the same machine. One team’s reasonable recovery operation lands as an unexplained latency spike for a completely unrelated service. You need isolated broker pools for workloads with genuinely different profiles.
Furthermore, all dead-letter queues need owners. You shouldn’t try to find the owner during an incident. The technical part is easy. You catch the exception and route the message somewhere else. The operational part is almost always the one that bites. No alert on depth, no metadata explaining why the message failed, no redrive tooling. Months later, the topic has millions of messages, and the context needed to fix them is long gone. You just lost your data in a fancier way.
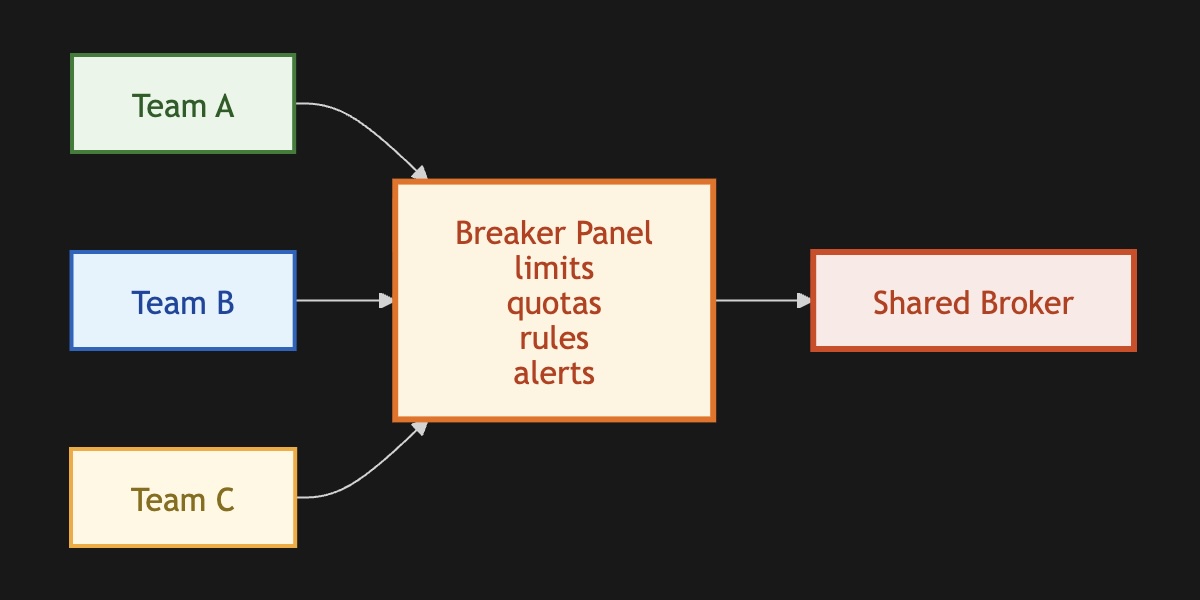 Message Broker Breakers Panel
Message Broker Breakers Panel
Operating A Grid
A shared broker creates a small organizational trap. Product teams make many of the load decisions. Supporting teams own much of the reliability.
The product team chooses the topic, the key, the retention, the payload size, the retry behavior, the consumer logic, and whether replay is safe. The supporting team gets paged when the cluster is slow, the disks fill, consumer lag explodes, or a noisy tenant hurts unrelated services.
If the team creating the load does not feel the cost, the operating team becomes a kind of grid police. They chase orphaned topics, bad partition counts, infinite retention, broken consumers, expensive replays, and clients that behave badly under broker pressure.
That is not a healthy model. It is centralized pain with a cleaner interface. A better platform does not rely on people remembering all the rules. It makes the safe path easier. It gives teams self-service, but self-service with guardrails. It lets teams move quickly without giving everyone raw access to overload shared infrastructure.
The broker is still useful. That is the reason it becomes dangerous. Useful infrastructure attracts more use, more clients, more exceptions, and more creative abuse. The moment the broker becomes the grid, we need to ask different questions. It is no longer enough to ask a typical message per minute question. The harder question is whether the platform can absorb new loads without letting one team's plan B become someone else’s brownout.