I have been working on this data discovery tool for a while, and it keeps showing me how messy our systems really are. The idea behind it is simple. Crawl every database we have, pull every table and column, match things that look the same across Postgres, Hive and Redshift, and then put everything in one place. One stop shop for metadata. That’s how I sold the idea by the way.
The more I work on it, the more I realize how often things break without anyone noticing. Tables drift out of sync. Columns get renamed. Hive has one version of a table, Postgres has another, and Redshift has something half-related that someone created years ago. Most of the documentation is pure horse shit. Some tables are replicated in three places without a single person aware of all three. Fucking amazing!
Building this tool made one thing very obvious. Logging and monitoring matter a lot more than we think. They are the only reason I can even understand what the hell is happening in this giant mess.
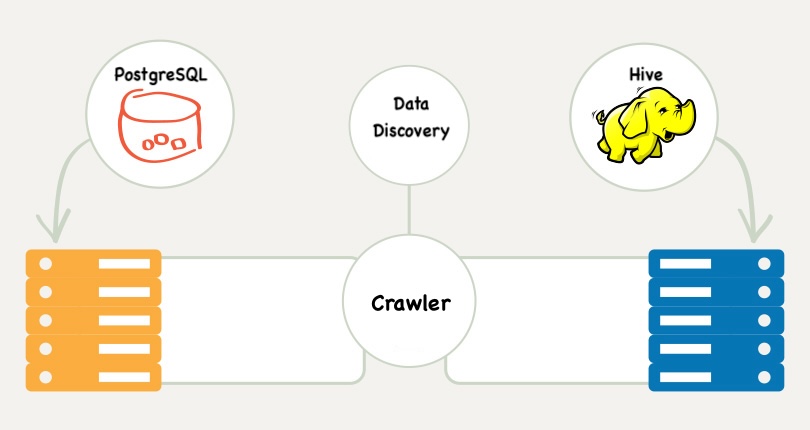 Data discovery tool crawling everything
Data discovery tool crawling everything
Until You Crawl Everything
The very first crawl made it painfully clear that nobody actually knows what the hell we have. Everyone thinks they do, but once you crawl every database, the picture looks completely different. There are tables nobody remembers. Tables that were copied years ago and never used. Tables that exist in Hive, Postgres and Redshift but look nothing alike. Tables with the same name but completely different meaning. It is a mess that you only see when you collect everything in one place.
The tool is not doing anything clever at this point. It is literally just reading metadata. But even that simple job is enough to show how unstructured everything really is. You open a schema and find hundreds of tables with zero documentation. You open a table and the columns might as well be called nothing, because the names tell you absolutely nothing. Some tables look like they were built twice, by two different people, at two different times, and neither of them ever spoke to each other. You never see this chaos until a crawler hits every corner of your data.
Seeing all of this together in one interface is interesting at the very least. You realise how much tribal knowledge people rely on. You realise how many assumptions are wrong. You realise the company has multiple versions of the same truth without anyone noticing. The discovery step alone shows more problems than any meeting ever will.
What Changed Since Yesterday
Discovering everything once is already painful. Keeping track of how it all changes is even worse. Schemas drift constantly. Someone adds a column in Postgres and nobody updates the Hive version. Redshift tables fall behind. A team drops a table without telling anyone. New tables appear overnight because someone pushed a pipeline at 2 AM. None of this is visible unless the tool keeps a history.
This is where logging and monitoring inside the tool matter. Every crawl is a snapshot. The tool compares snapshots and shows exactly what changed. A missing column. A renamed field. A table that used to have 3 partitions and now has 10. A schema that suddenly doubled in size.
The tool has to log every mismatch and every difference it finds. If it does not, your so-called single source of truth is already stale the second you open it. Discovery tells you what exists, but version tracking shows how fast it all slips and shifts underneath you. Without both, you are basically lying to yourself.
Good Logs is the Differentiator
None of this is possible without good logging. The crawler touches multiple systems, and each system breaks in its own special way. Hive might skip a partition. Redshift might time out. A JDBC driver might throw a useless error. A table might not respond at all. Without a detailed log of every step, you would have no idea what happened or where it failed.
Logs also save you when the metadata is wrong. A column might claim to be an integer when the actual data is something else. A schema might say a table exists when it really does not. Some tables have corrupted metadata that only shows up when the crawler hits them. If the tool does not log these things clearly, you end up guessing, and guessing does not work when you are dealing with dozens of databases.
At the end of the day, logging is the thing I come back to. It tells me what the crawler saw. It tells me what broke. It tells me what changed. It is the only way to trust the output of a tool that depends on so many moving parts. Without good logs, I am just crawling in the dark.
In Consequence
Working on this discovery tool made me realise how much we depend on logging and monitoring without even knowing it. Discovery shows the mess we have. Tracking changes shows how fast that mess moves. Logging is the only reason any of it makes sense. Without logs, the tool would look broken every day, and without monitoring the snapshots, the source of truth would go stale immediately.
Most of the problems were never about the code or who wrote it. They were about hidden tables, drifting schemas, missing metadata and systems that behave differently depending on when you touch them. The only way to deal with all of that is to see everything, record everything and keep a history of what changed. That is why logging and monitoring matter so much. They are not nice to have. They are the only way a tool like this can work at all.