Executing update statements on a production database is always a big challenge. It’s one of those tasks that looks deceptively simple until something breaks in ways you didn’t imagine. I have seen three different prominent incidents due to update problems. In each one of the incidents, multiple factors lead to the incident. Human error, missing safeguards, and time pressure often compound in subtle ways.
I remember once we wanted to update the production database during an upgrade. Somehow, we lost both the main database and its backup. The only thing that survived was a backup of the backup that AWS had preserved. I got paged for it in the middle of the night, completely baffled, only to realize later that we had never actually tested how our backups worked.
We could have avoided these problems by a couple of preventive actions and a bit of engineering rigor. A few disciplined steps before, during, and after execution can make the difference between a clean deployment and a production fire.
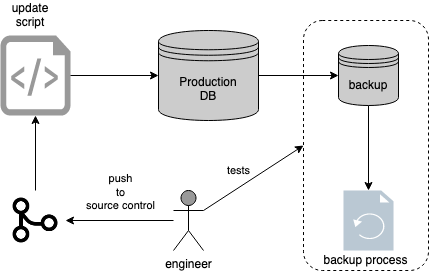 Database update process
Database update process
Before Running Update Statements
One of the causes for update statement incidents is overconfidence or lack of meaningful process. Engineers can take it for granted that they figured out how to do the update. Confidence is good, but production doesn’t reward assumptions. It only rewards preparation. Nevertheless, updates may work 99 times. At one last time, it might fail and fail miserably. And when it fails, it often fails in ways that ripple across systems, alerts, and dashboards all at once. Murphy's Law.
Anything that can go wrong will go wrong.
Hence, it's better to be prepared and put together a process to avoid such nightmares. It’s not paranoia; it’s resilience.Here is a gentle procedure.
- Send a code review request for every update statement/script.
- We can avoid inefficiencies by getting a code review. A reviewer can question intent, verify edge cases, and often spot typos that could have been catastrophic.
- A second eye can catch an obvious mistake.
- Get a database dump and run the query on a test database.
- Sample the database when the tables are way too big.
- You can correct problems further by running against the test database. If the test version doesn’t behave as expected, production won’t either.
Treat every update as if it could destroy production because it simply can.
While Running Update Statements
There are a couple of things that we could do to avoid such update problems. Here are some rules I use for production databases. These are the habits that separate calm midnight pages from chaotic ones.
- Run a select query on the update and confirm the counts as expected before running the original update. There are three reasons for this.
- The number of updates can take down the database because of row-level lock. If the database has multiple replicas, it becomes even more necessary.
- The select query gives a sense of running time for the update query. If select is slow, it would be an order of magnitude slower for the update.
- Lastly, see if the update query meets our expectations. Think of this step as a dry run. A safety rehearsal before the real show.
- Always run an update query with transactions on a production database. Start with BEGIN and end with a COMMIT.After running the update query in a transaction, put a couple of validation queries. ROLLBACK if itʼs needed. A transaction gives you an undo button in a world where undo rarely exists.
- Pair up with another engineer while running the critical update statements. It’s harder to make mistakes when someone’s watching. It’s even better when that someone is equally paranoid.
Even a well-written query can go wrong in production. Locks, replication lag, triggers, and timing can turn a “harmless” update into a nightmare. The key is to run slowly, validate constantly, and never assume success until after COMMIT.
Proactive Actions on Databases
We can expect engineers to do the right thing. Nevertheless, experience keeps proving that even the best intentions can go sideways under pressure. One might forget a step or get distracted. We need to be ready to deal with such scenarios. The goal isn’t to eliminate failure. Our goal is to make recovery fast, predictable, and painless.
Here are the things we could do.
- Keep a backup. You can get 5 minute backups to daily backups depending on the database. Shorter backup intervals cost more, but they buy peace of mind when things go wrong.
- Get a backup of a backup. Write the contents to some file system or object storage. Store backups in separate accounts. If you use one cloud or on-premise database, use a different cloud provider for a secondary backup to avoid downtime issues. In other words, don’t trust a single cloud, a single region, or a single engineer.
- Prepare a runbook.Have steps documented for database updates. Play runbooks every once in a while to test if the steps in the runbook still work. Runbooks age quickly, especially when systems evolve. Regularly rehearsing them keeps your process alive and your team confident.
Incidents will happen. What defines a strong engineering culture isn’t the absence of failure but the calm, structured response when it arrives. Backups, runbooks, and tested recovery paths turn panic into procedure.
A Checklist for Production Updates
Here’s a quick checklist for updates:
Before running updates
- Review your query with a peer.
- Test on a dump or a sampled copy of the database.
- Estimate row counts and runtime with a select query.
While running updates
- Always use transactions (BEGIN, COMMIT, ROLLBACK).
- Validate affected rows before committing.
- Pair up with another engineer during execution.
After updates
- Verify data integrity.
- Document what changed and why.
- Update runbooks or automation if something was learned.
Simple. Boring. Life-saving.
In Consequence
There’s no such thing as a harmless update in production. Every query, no matter how small, touches history, revenue, or trust. When you treat it with the respect it deserves, you build systems and habits that last.
Most production fires aren’t caused by bad intent, but by missing humility. I know it very well because I’ve done it myself. Slow down, double-check, and assume nothing. It’s the quiet discipline that keeps everything else running.